Introduction
In this article we explain how a VMD file for an HL7 ADT message works.
In the Iguana Translator, two built-in functions use a VMD file when processing incoming messages:
hl7.parse()uses the VMD file to parse the messagesdb.tables()uses the VMD file to determine what database tables record structure to create
If you have any questions about using Chameleon please contact us at support@interfaceware.com.
Note: The demo.vmd file supplied with different versions of Iguana has changed over the years — so yours may not exactly match the one used here (but it will be similar).
You can download this version of demo.vmd which is the one we use on this page.
Understanding VMD Files
To understand how the hl7.parse() function uses the VMD file to parse incoming messages, we will use Chameleon to open and view the demo.vmd file.
- Open the VMD file from within Iguana.
- Open any channel that uses demo.vmd.
- Hover over the small “arrow” to the right of the demo.vmd and choose Get from the menu:

- Choose the Open option to open the file with Chameleon:

- Alternatively you can download the demo.vmd file and open it from file explorer:

- The file will open in Chameleon, you should see something like this:

- There are three message definitions defined in this file, ADT, Lab and Catchall:
Messages are displayed in the workspace at the left of the Chameleon window — along with other items like Tables and Segments etc.
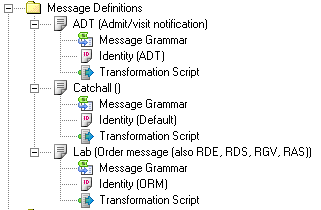
- Each message definition has an Identity defined for it.
The Identity determines what messages are to be processed by this message definition. Click on Identity definition to view its definition.
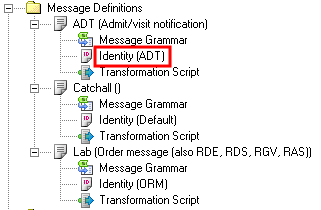
- Click on Identity (ADT) to view its definition, this dialogue appears:
The Segment column indicates that the segment to be examined is the MSH segment. The Field column indicates that the first subfield of Field 9 of the MSH segment is to be examined. The Value column indicates that the message is processed if this subfield has the value ADT.

Note: When you are creating a VMD file to be used by a Iguana Translator mapping script, and you are creating an Identity for a message definition for this VMD file, the Identity does not need to be too specific. For instance, specifying an Identity that matches the first subfield of Field 9 is usually sufficient. (In this example, this is ADT.)
If you are expecting to process multiple message with the same message code (for example, ADT^A04 and ADT^A31), you can use the Iguana Translator mapping script to distinguish one type of message from another. You do not need to define a separate definition for each message type
- Each Message Definition also contains instructions for how a message that matches its Identity is to be processed:
This set of instructions is called the Message Grammar. Each Message Grammar consists of two parts: the Segment Grammar, which indicates the segments that the vmd file is expecting the message to contain, and the Table Grammar. You will only need to look at the Segment Grammar.
- To view the Segment Grammar for the ADT message definition, click Message Grammar:
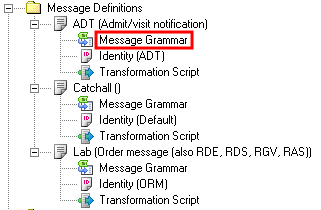
- A Message Grammar window appears, with the Segment Grammar displayed in the left panel of the window:
The Segment Grammar lists the segments that the ADT message definition is expecting its messages to contain.

- Segments whose type is enclosed in brackets [ ] (for example, [PV2]) are optional:

- Segments enclosed in angle brackets < > (for example, <OBX>) are repeating (may occur zero or more times):

- All segments not listed in the Segment Grammar are ignored if the Ignore segments not in grammar check box is selected.
- The Segment Grammar may contain any number of segment groups.
Each segment group consists of one or segments that are grouped together. In this Segment Grammar a segment group named PROCEDURE is defined. This group contains one PR1 segment and zero or more ROL segments.

- Segment groups, like segments, can be either optional (enclosed in brackets [ ]) or repeating (enclosed in angle brackets < >):
In this example, both the PROCEDURE and INSURANCE segment groups are repeating, which means that they may occur zero or more times.
- To view the Segment Grammar for the ADT message definition, click Message Grammar:
To understand how db.tables() uses the VMD file to create the database tables to be mapped to, take a look at the Tables section of the Workspace panel of the demo.vmd file:
- In the Message Definition pane you can see that two tables are defined: kin (for next-of-kin data) and patient (for patient data).
These are the tables that
db.tables()creates when it is called.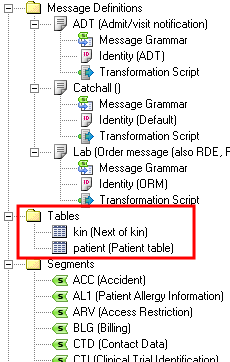
-
To view the fields defined in a table, click its entry in the Tables section.
-
For example, here is the Table window for the patient table:
The Column Name column lists the fields that are defined in this table, the Data Type column shows the data type of the fields.

- Using the
db.tables()function in translator script creates an empty table record structure that reflects the VMD tables structure:Your Iguana mapping script will populate some or all of these fields with data mapped from the incoming messages.
