Method One: Import Excel or CSV
Contents
This example shows how to process CSV or Excel files with Iguana. The data and project files are here.
Limitation: unfortunately when Iguana is run as a service on Windows 7 the script for converting xls files to CSV does not work (and probably will not work with Vista). This appears to do with the increased security/access restrictions that Windows 7 places on Services. The workaround is to run Iguana from the command line as iguana --run when using Windows 7. We will update this section when we find a solution.
A From Translator is used to load the file into Iguana:
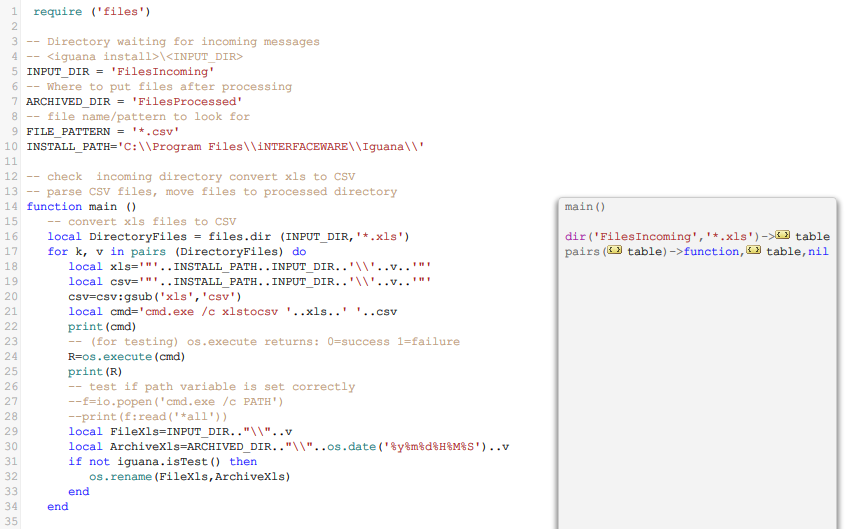
Tip: Because we do not want rename the the file while we are using the editor (test mode), we used iguana.isTest() to prevent the rename.
Basically there are four steps:
- Convert the xls file to CSV.
- Limitation: conversion fails on Windows 7 (and probably on Vista).
- Workaround: run Iguana from the command line as
iguana --run.
- Read the CSV file.
- Queue the file.
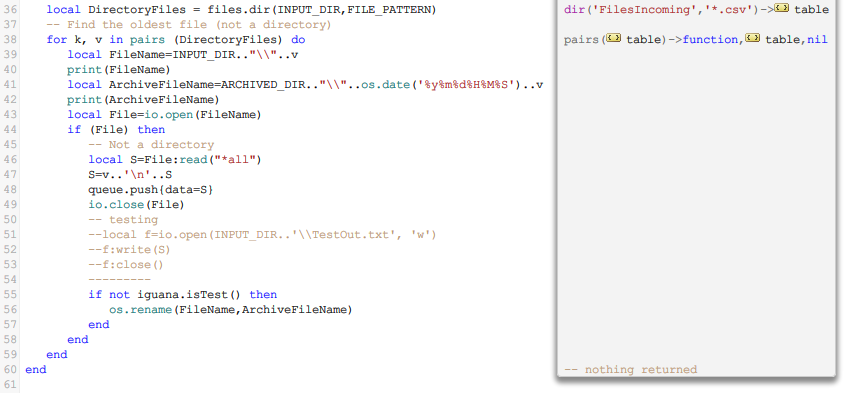
- Finally move the file to a “processed” directory.
In this case we queued the whole file as a text string, all the processing will be done later in the To Translator. It is regarded as best practice to do the minimum of processing in the From Translator.
The first step has a few gotchas so please read how to convert the xls file to CSV, also it converts xls files with single or multiple sheets.
You will notice that I identified the file that was loaded by adding the file name at the begining of the string before I queued it. I will use the file name to identify files in the To Translator and then apply different filtering or processing as required. Also I exported the queued data to a file, so I can use it to test the From Translator code. The reason this is needed is that the queuing mechanism only works when the channel is running, so you need to load some sample data for the To Translator.
A To Translator is used to process the data:
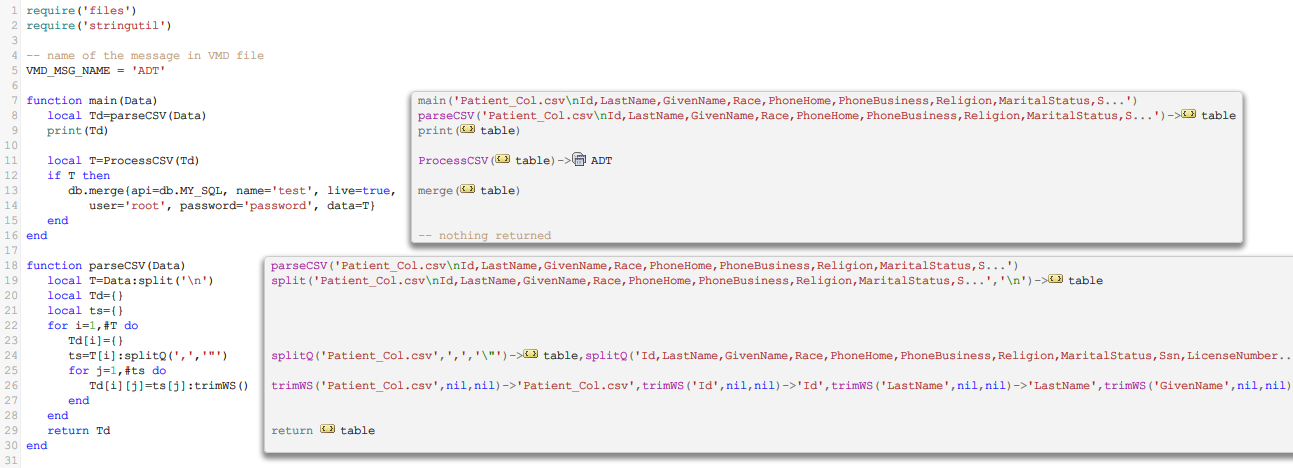
Tip: For improved CSV parsing use our csv module, see the How to Parse a CSV File tutorial, and the Parsing CSV Files code sample pages.
As you can see the process is fairly simple: split data into rows separated by “\n” and then split the rows into columns separated using standard CSV separator and qualifier (comma “,” and double quote “””) .
Now we have a table Td that reflects the structure of the Patient table in our database.
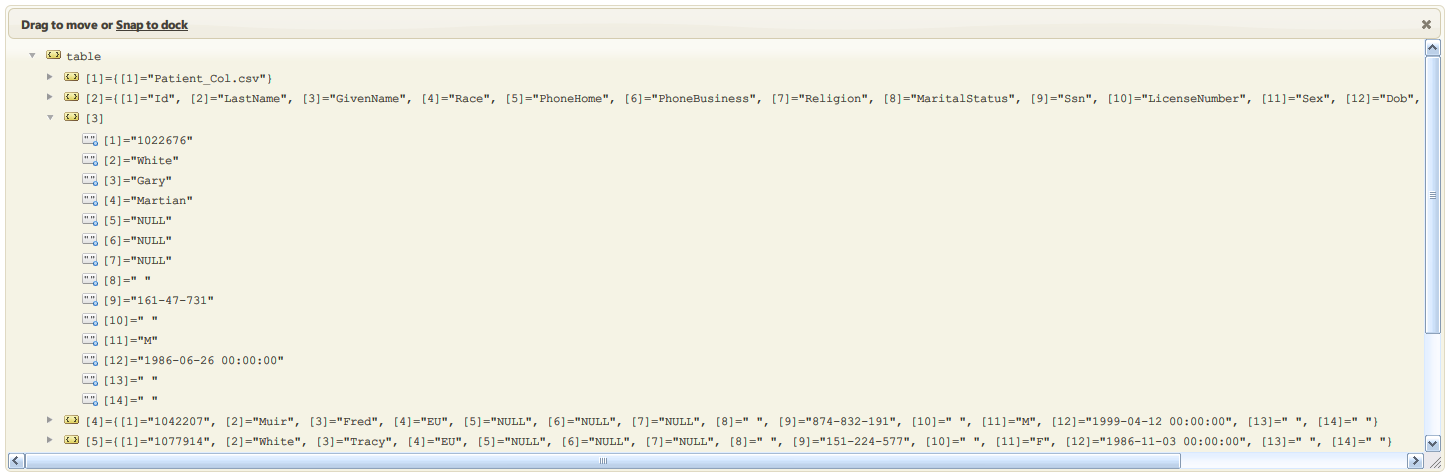
Now all that remains is the mapping process. As you can see the first row contains the file name and the second contains the field names. Because of this the mapping will need some logic to avoid loading these rows into the database.
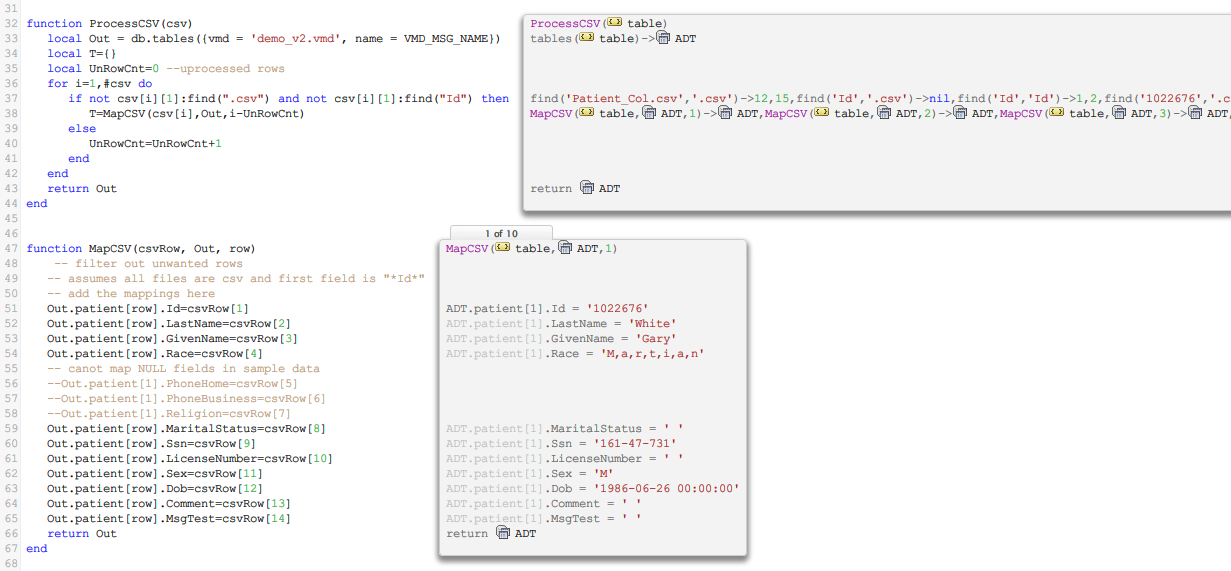
As you can see from this example it is easy to filter out unwanted data, the first two rows in this case. The filtering required in a live system will probably be considerably more complex,. In that case it might be easier to process the data in several steps and delete unwanted rows before mapping. Also you can see that Gary White is a M,a,r,t,i,a,n indicating that “M,a,r,t,i,a,n “, in the CSV was correctly processed.
Code that you can copy is below, or you can download the data and project files here.
From Translator:
require ('files')
-- Directory waiting for incoming messages
-- <iguana install>\<INPUT_DIR>
INPUT_DIR = 'FilesIncoming'
-- Where to put files after processing
ARCHIVED_DIR = 'FilesProcessed'
-- file name/pattern to look for
FILE_PATTERN = '*.csv'
INSTALL_PATH='C:\\Program Files\\iNTERFACEWARE\\Iguana\\'
-- check incoming directory convert xls to CSV
-- parse CSV files, move files to processed directory
function main ()
-- convert xls files to CSV
local DirectoryFiles = files.dir (INPUT_DIR,'*.xls')
for k, v in pairs (DirectoryFiles) do
local xls='"'..INSTALL_PATH..INPUT_DIR..'\\'..v..'"'
local csv='"'..INSTALL_PATH..INPUT_DIR..'\\'..v..'"'
csv=csv:gsub('xls','csv')
local cmd='cmd.exe /c xlstocsv '..xls..' '..csv
print(cmd)
-- (for testing) os.execute returns: 0=success 1=failure
R=os.execute(cmd)
print(R)
-- test if path variable is set correctly
--f=io.popen('cmd.exe /c PATH')
--print(f:read('*all'))
local FileXls=INPUT_DIR.."\\"..v
local ArchiveXls=ARCHIVED_DIR.."\\"..os.date('%y%m%d%H%M%S')..v
if not iguana.isTest() then
os.rename(FileXls,ArchiveXls)
end
end
local DirectoryFiles = files.dir(INPUT_DIR,FILE_PATTERN)
-- Find the oldest file (not a directory)
for k, v in pairs (DirectoryFiles) do
local FileName=INPUT_DIR.."\\"..v
print(FileName)
local ArchiveFileName=ARCHIVED_DIR.."\\"..os.date('%y%m%d%H%M%S')..v
print(ArchiveFileName)
local File=io.open(FileName)
if (File) then
-- Not a directory
local S=File:read("*all")
S=v..'\n'..S
queue.push{data=S}
io.close(File)
-- testing
--local f=io.open(INPUT_DIR..'\\TestOut.txt', 'w')
--f:write(S)
--f:close()
---------
if not iguana.isTest() then
os.rename(FileName,ArchiveFileName)
end
end
end
end
To Translator:
require('files')
require('stringutil')
-- name of the message in VMD file
VMD_MSG_NAME = 'ADT'
function main(Data)
local Td=parseCSV(Data)
print(Td)
local T=ProcessCSV(Td)
if T then
local conn = db.connect{
api=db.MY_SQL,
name='test',
user='root',
password='password',
live=true
}
conn:merge{data=T, live=true}
end
end
function parseCSV(Data)
local T=Data:split('\n')
local Td={}
local ts={}
for i=1,#T do
Td[i]={}
ts=T[i]:splitQ(',','"')
for j=1,#ts do
Td[i][j]=ts[j]:trimWS()
end
end
return Td
end
function ProcessCSV(csv)
local Out = db.tables({vmd = 'demo_v2.vmd', name = VMD_MSG_NAME})
local T={}
local UnRowCnt=0 --uprocessed rows
for i=1,#csv do
if not csv[i][1]:find(".csv") and not csv[i][1]:find("Id") then
T=MapCSV(csv[i],Out,i-UnRowCnt)
else
UnRowCnt=UnRowCnt+1
end
end
return Out
end
function MapCSV(csvRow, Out, row)
-- filter out unwanted rows
-- assumes all files are csv and first field is "*Id*"
-- add the mappings here
Out.patient.Id=csvRow[1]
Out.patient.LastName=csvRow[2]
Out.patient.GivenName=csvRow[3]
Out.patient.Race=csvRow[4]
-- canot map NULL fields in sample data
--Out.patient[1].PhoneHome=csvRow[5]
--Out.patient[1].PhoneBusiness=csvRow[6]
--Out.patient[1].Religion=csvRow[7]
Out.patient.MaritalStatus=csvRow[8]
Out.patient.Ssn=csvRow[9]
Out.patient.LicenseNumber=csvRow[10]
Out.patient.Sex=csvRow[11]
Out.patient.Dob=csvRow[12]
Out.patient.Comment=csvRow[13]
Out.patient.MsgTest=csvRow[14]
return Out
end
Shared files module:
Note: In Iguana version 5.6.16 we added the string.split() function to Iguana’s standard string library to split strings on a specified delimiter, this removes the stringutil module dependency.
If you are using a version before 5.6.16 you can use string.split() function in the stringutil module.
files = {}
function files.dir(Dirname, FileName)
local TmpName = os.tmpname()
TempFileName = string.sub (TmpName, 2)..".tmp"
os.execute("dir /B /TW "..Dirname.."\\"..FileName.." >"..TempFileName)
local f = io.open(TempFileName, "r")
local rv = f:read("*all")
f:close()
os.remove(TempFileName)
return rv:split("\n")
end
function string.split (Data, Delimiter)
local Tabby = {}
local From = 1
local DelimFrom, DelimTo = string.find( Data, Delimiter, From )
while DelimFrom do
local FileName = string.sub (Data, From, DelimFrom-1)
-- Do not add the temp file we just created
table.insert( Tabby, string.sub( Data, From , DelimFrom-1 ) )
From = DelimTo + 1
DelimFrom, DelimTo = string.find( Data, Delimiter, From )
end
table.insert( Tabby, string.sub( Data, From) )
-- delete blank last row (from trailing delimiter)
if Tabby[#Tabby]=="" then Tabby[#Tabby]=nil end
return Tabby
end
-- split qualified string to table
function string.splitQ (Data, Delimiter, Qualifier)
if Qualifier==nil or Qualifier=='' then
return string.split (Data, Delimiter)
end
local s=Data
local d=Delimiter
local q=Qualifier
s=s..d -- ending delimiter
local t = {} -- table to collect fields
local fieldstart = 1
repeat
-- next field is qualified? (start with q?)
if string.find(s, '^'..q, fieldstart) then
local a, c
local i = fieldstart
repeat
-- find closing qualifier
a, i, c = string.find(s, q..'('..q..'?)', i+1)
until c ~= q -- qualifier not followed by qualifier?
if not i then error('unmatched '..q) end
local f = string.sub(s, fieldstart+1, i-1)
table.insert(t, (string.gsub(f, q..q, q)))
fieldstart = string.find(s, ',', i) + 1
else -- unqualified - find next delimeter
local nexti = string.find(s, d, fieldstart)
table.insert(t, string.sub(s, fieldstart, nexti-1))
fieldstart = nexti + 1
end
until fieldstart > string.len(s)
return t
end