- Introduction
- Non-comformant dates
- Parsing formatted text
- Mirroring a Fogbugz Wiki
- Configuring Linux IPChains for a redundant DSL connection
Introduction
This article was originally written for Iguana 5 so it uses version 5 screenshots, and may contain some outdated references.
There are a lot of weirdo messaging formats out there in the healthcare market. The Iguana Translator is a killer tool for handling all sorts of formats. If you have something which is a bit unusual, let us know, we like a challenge to show off how powerful the Translator is.
Non-comformant dates [top]
Problems with dates are so common that we created the fuzzy date/time parser module especially to help. See the fuzzy date/time parser for more information, also you can download the the code from our builtin Date/Time repository.
Parsing formatted text [top]
How do we build a simple function to extract information from plain text file?
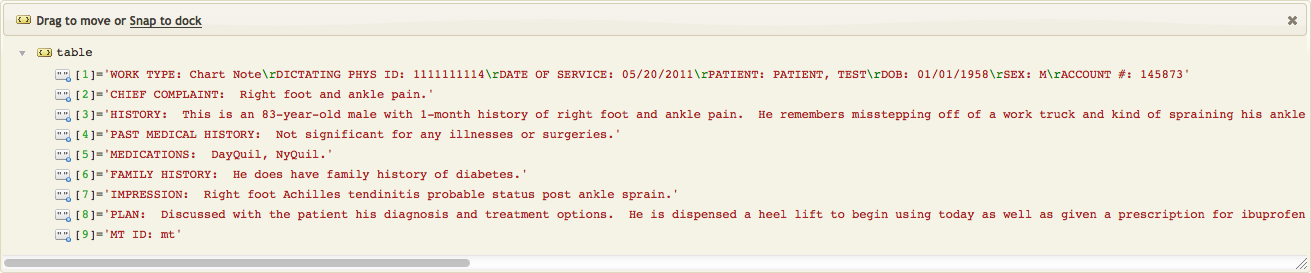
Say we wish to split by empty lines, indicating new paragraphs:
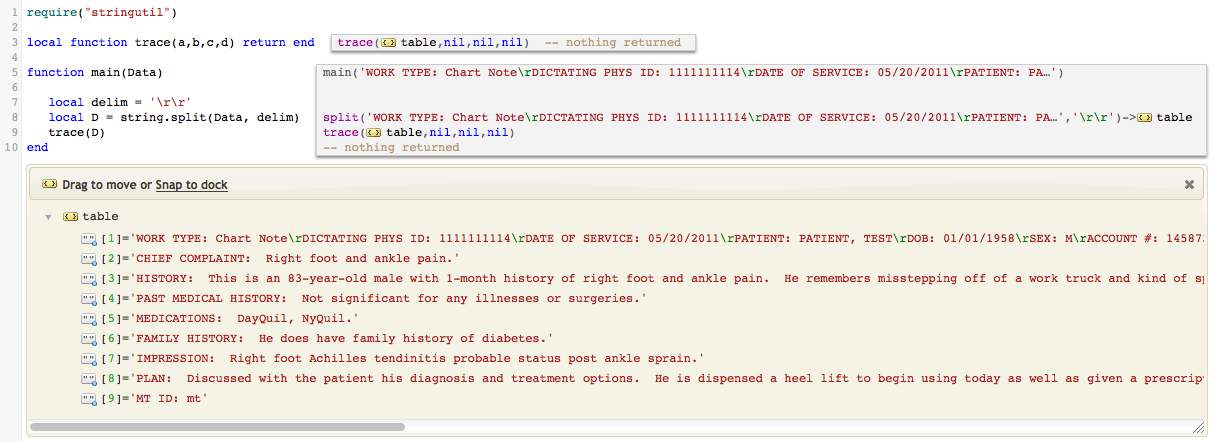
Or we can for split by a substring:
- Search for the header string, for example “PAST MEDICAL HISTORY”
- Extract the information out after the colon
- Use each paragraph as values for say numerous OBX-5 fields in HL7 message
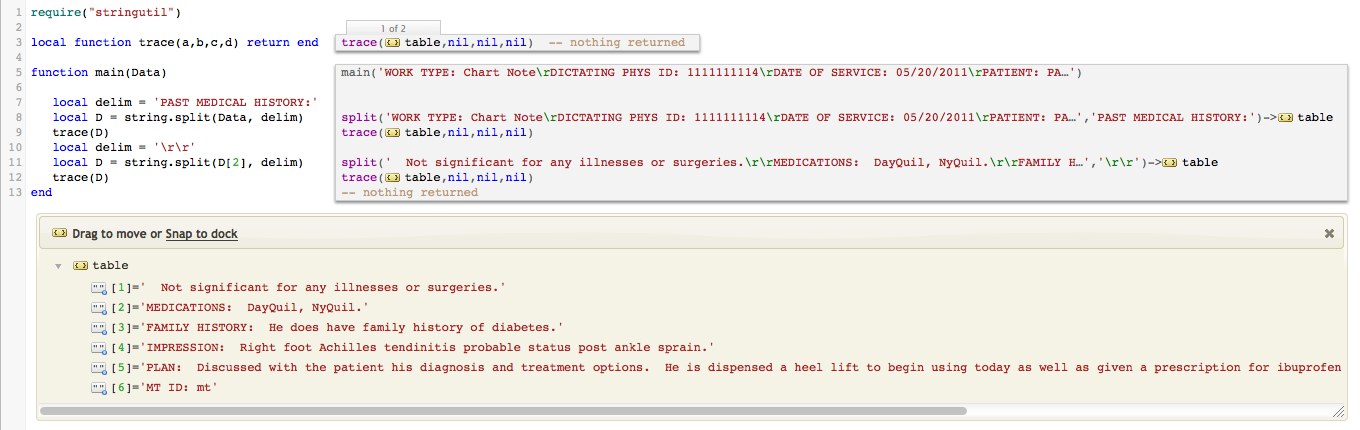
Or we can for split by several substrings:
- Search for the header string, for example “MEDICATIONS”
- Extract the medicines information out after the colon
- Use medicines names as values for HL7 messages
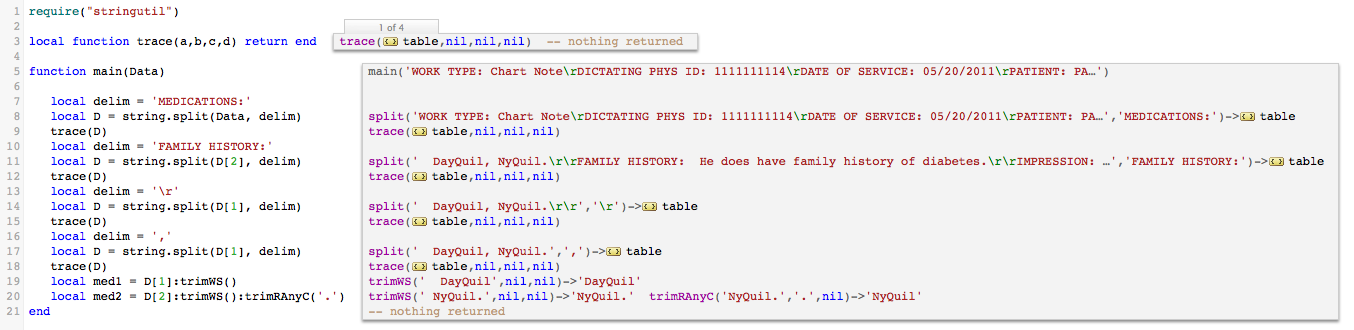
The project can be imported from this zip file Parse_text_file.zip, the test data is included.
Functions string.split() and string.trimRAnyC() could be included in any module, we included then in stringutil, as it seems like a good candidate
Mirroring a Fogbugz Wiki [top]
Note: We are now using WordPress for our documentation instead of Fogbugz.
This is a very interesting application of the Translator that falls completely outside of the traditional realm of interfacing.
This wiki is implemented using a commercial product called Fogbugz which is an excellent bug tracking system which has a nice wiki combined with it. However we use Iguana to programmatically extract the data from that wiki and reformat in the manner you see now.
There is a lot to love about the Fogbugz wiki as a documentation solution. It has a very intuitive interface and it is simple to jump in and be productive with it. Unlike most wikis the Fogbugz wiki has a great concept of having a page hierarchy which is allows us to structure the documentation in a similar fashion to our old manual. Page editing is WYSIWYG, it feels just like using Word in the context of a browser.
But there are things that were not ideal that our old manual technology already offered such as:
- Serving pages quickly because all the final generated output was static HTML. We have had reports from customers in some parts of the world like India and Singapore that the Fogbugz wiki had quite slow performance in their areas.
- It’s hard to proxy the Fogbugz wiki to our own internet domain name, to use the URL wiki.interfaceware.com it requires a few roundtrips to redirect to the Fogbugz URL which was interfaceware.fogbugz.com.
- Hard coded links to http://interfaceware.fogbugz.com crept into the wiki which were difficult to find and remove.
- If you were looking at http://wiki.interfaceware.com/ then logging and editing the wiki had an awkward work flow.
- We wanted back the tree navigation on the left hand side of the page the Fogbugz wiki:
- Only showed some of the related page siblings
- Sibling pages were always given in alphabetical order rather than giving us control over the order, it was a small but very significant usability issue.
- The Fogbugz wiki didn’t give us next and previous buttons, these are very useful for customers going through tutorials.
- It’s hard to get precise control over the complete look and feel of the wiki. We did our best but the Fogbugz skinning system limited what we could do.
Overall we like Fogbugz a lot better than our original home grown documentation system. But the above issues were significant for our customers, having good available documentation is a big differentiator for us and so these issues are very important to fix.
So we decided to use Iguana to fill the gap and it’s turned out to be a beautiful solution. It’s very easy to use Iguana to scrape the Fogbugz wiki to extract our document data and render a static HTML version of the site with complete control over all the formatting.
What you are reading right now is the content generated by Iguana from programatically extracting data from the Fogbugz wiki. This attached image shows what the Original Format.png looked like.
Curious to see of how much interest this is for people, let us know.
Source Code
Dmitri kindly made this code available. Obviously this is a starting point to play with which will require customization to fit your own environment. If you are interested in using the code and discussing it then our Linked In forum group is a great place to come to do that. Please contact our support if you would like to become part of that group.
sample_GenerateHandler_To_Translator.zip: Processes messages by fetching pages from source FogBugz instance, parsing pages, computing hierarchy and generating output HTML
sample_PeriodicUpdate_From_Translator.zip: Periodically (on a schedule) produces messages indicating GenerateHandler to regenerate the data, and sometimes completely retransfer pages.
sample_RecentlyChanged_From_Translator.zip: Caches data from Recently Changed pages, generates output pages
sample_UpdateRequest_From_HTTPS.zip: Handles HTTP request indicating to update a particular page immediately (called by URLTrigger plugin from fogbugz whenever a user edits and saves a page).
sample_EditRedirect_From_HTTPS.zip: Handles the “Edit” link redirect, protecting it with a password, to conceal the original instance from getting visited by search engines etc.
Dmitri would like to make some site-specific customized static “skinning” files, to polish off the appearance, animate tree menu etc., a generic version might be coming up later.
How it works
GenerateHandler contains the core caching logic, it accesses the FogBugz instance via HTTP/XML API or by fetching the pages like a normal browser, parses the pages, works out the hierarchy tree, and finally generates and writes output HTML files.
It gets messages (effectively instructions, commands) from various other channels, which tell it to do various tasks, for example:
- Re-transfer a particular page:
FetchPageId=123 -- re-fetch page 123 and regenerate
- Or re-transfer all pages:
FetchPageId=*
- regenerate using data already fetched and stored locally, if available (useful for testing generation)
FetchPageId=#
Configuring Linux IPChains for a redundant DSL connection [top]
This is about the most off the wall application of the Translator I have heard of.
Dmitri who is a member of our development team and also has a part time role administering our infra-structure. Dmitri is a real linux guru.
We tried a number of off the shelf redundant networking solutions to try and have 3 DSL gates into our office so ensure we have reliable internet access to our location.
These solutions didn’t really work and personally I would have happy enough to pick an adequate solution of a run of the mill router with manual fail over (aka sneaker net in the case of failure). Dmitri how ever figured out how to leverage Linux IP Chains and set up this crazy home grown redundant network routing solution based on Linux. It’s always been a little scary to me to be honest since I wasn’t confident that anyone but Dmitri could maintain this system.
My main peace of mind was it that in the big picture it was best to give Dmitri free rein since he’s highly competent at keeping things ticking over smoothly but that if he left we’d probably just end up settling with a lower level of network reliability and have a cheap router that we would need to reboot manually periodically.
But Dmitri surprised me, in September off his own initiative he completely rewrote his system in a couple of days and implemented it entirely in the Translator. And at this point it’s simple and obvious enough that anyone on the dev team including myself can actually understand the system. It’s visible and easy to understand.
That really is the entire point of the Translator, give a powerful efficient tool to solve problems, but in a manner which makes it easy and transparent for a team to support.
Dmitri is happy because he’s allowed to implement a great technical solution, and I’m happy because I know we’re going to be okay when he is on holiday.
So if you wondering, can the Translator work to integrate my Acme 2000 EMR? Don’t worry, relax, we use it to solve a lot weirder and tougher problems than just doing a bit of mapping.
Eliot Muir,
CEO of iNTERFACEWARE